Assignment 2
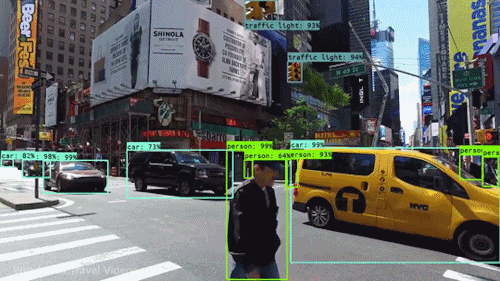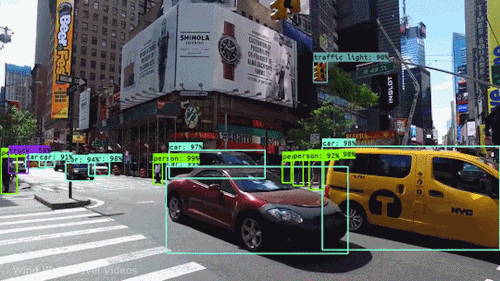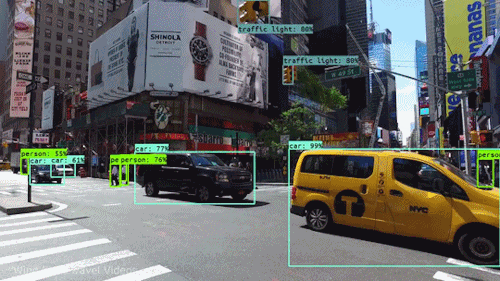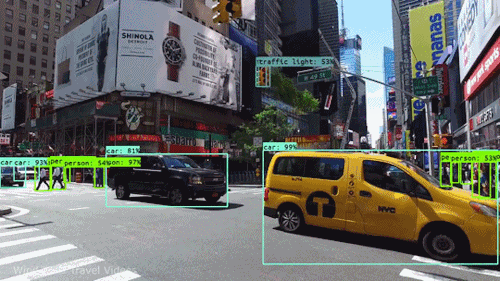
This assignment is due on April. 29, 2022 at 11:59pm UTC+8.
Please download all materials from
or (
and
) or
Note that if you download from Tsinghua Cloud, you need to download all the files from two link and run a command cat materials.tar.gz.part_a* > materials.tar.gz to get the complete file. The md5 for part_a is 400dbef9be98cc6a67da73cb37fc4b4b and for part_b is 3913914b0e0955579019ac72a6a6b61e.
The provided materials contain standard dataset, external dataset, a template config file, a template
results.pkl and a simple README.md. Note that we have already provide data on all cluster machine, the path is /home/share_data/materials. Details of how to use cluster machine can be refer to
Following is the overall structure of your assignment.
- Introduction to the competition
- Getting Started
- Add Customized Dataset
- Data Analysis and Data Augmentation
- Model Designing and Optimizer Setting
- Model Ensemble
- Submitting your work
1. Introduction to the assignment
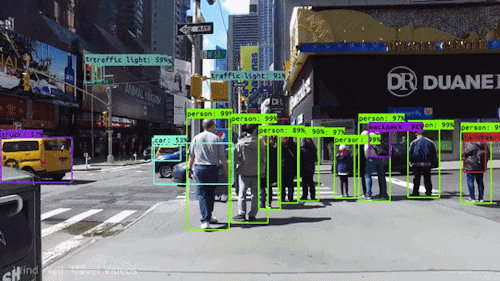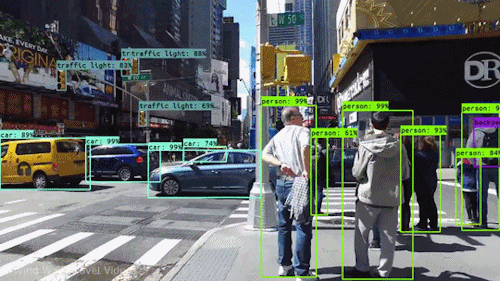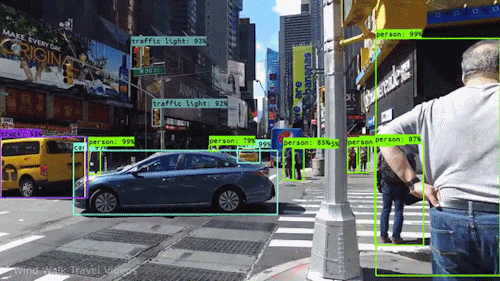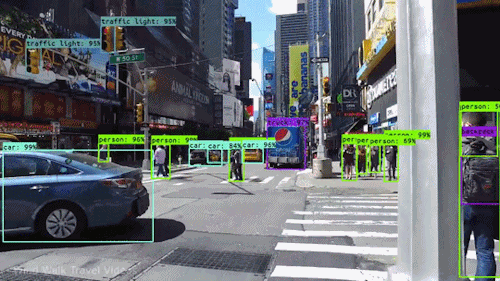
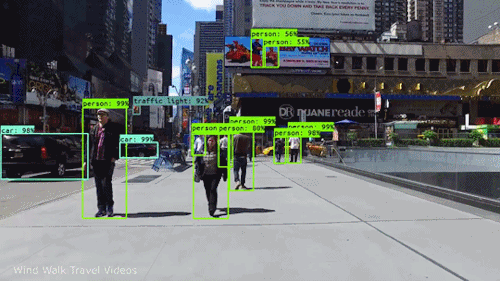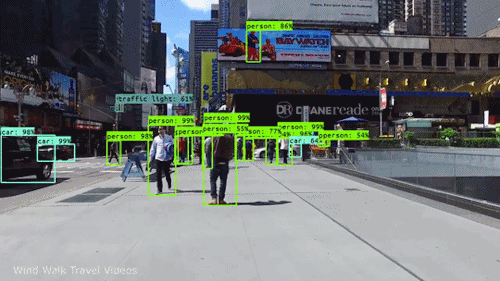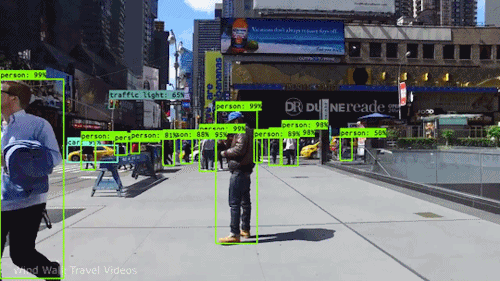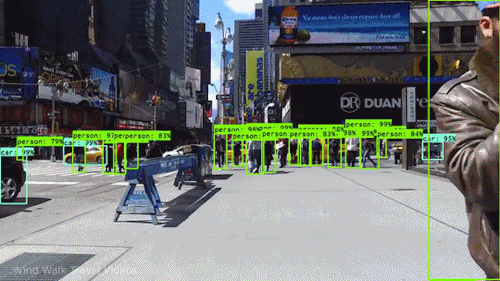
In this assignment, you are expected to handle an object detection task. The goal of this task is to recognize objects from a number of visual object classes in street scenes. The detection of foreground objects is among the most critical requirements to facilitate self-driving applications. 6 of the most common object classes have been selected, which are: 1). car; 2). person; 3). Van; 4). Cyclist; 5). Tram; 6). Truck. Note that there's an auxiliary category, DontCare, in the provided annotation, and this is NOT considered in final evaluation.
2. Getting Started
Install MMDetection Github Link.
Download datasets. The datasets are almost compatible to format of PASCAL VOC 2012. A sample config file is uploaded to Google Drive, too. You need to figure out how to modify the config file and some corresponding classes in the MMDetection framework to get it work.
| Name | Training | Validation | Testing |
| Object Detection | 2700 | 500 | 500 |
3. Add Customized Dataset. Bonus
Some competition allow the participators to utilize external data to improve the model's generalization ability and avoid over-fitting. In this competition, we provide another object detection dataset for you to extend your training set. Note that the provided external dataset is in kitti format.
Please refer to the docs in MMDetection and README.txt in the datasets.
4. Data Analysis and Data Augmentation
Is there any problem in data? Possible answers: long-tail problem, occlusion problem, multi-scale problem, etc.
Some data augmentation method can help eliminate these problems. e.g., random erasing (paper link) can improve the model's robustness to occlusion data. Please analysis the characteristic of datasets and implement some data augmentations.
5. Model Designing and Optimizer Setting
MMDetection categorizes model components into 5 types:
- backbone: usually an FCN network to extract feature maps, e.g., ResNet, MobileNet.
- neck: the component between backbones and heads, e.g., FPN, PAFPN.
- head: the component for specific tasks, e.g., bbox prediction and mask prediction.
- roi extractor: the part for extracting RoI features from feature maps, e.g., RoI Align.
- loss: the component in head for calculating losses, e.g., FocalLoss, L1Loss, and GHMLoss.
In this competition, we provide the results of Faster R-CNN baseline using default config file. You should try to improve at least one of a). backbone+neck; b). roi extractor; c). loss functions to achieve a better performance or shorter inference time than the baseline. Besides, we encourage the attempt at new paradigm for detection, likes OneNet (paper link) and SparseRCNN (paper link).
6. Model Ensemble. Bonus
Model ensemble is an effective technology to improve the final performance on machine learning task. A machine learning ensemble consists of a concrete finite set of alternative models. Usually, the more difference among them, the better final performance they achieve.
Please investigate and implement model ensemble or some other technologies often used in competitions.
7. Submitting your work
Your final grade depends on two aspects:
- You need to submit the detection results based on our provided testing set. We will evaluate the performance (AP&recall) of your model. Details of how to generate such a results.pkl can be referred from the README.md in materials.
-
You need to submit your final code project and corresponding report. The detail
of report can be referred from
template . You can also download fromGoogle Drive
Requirements:
- Please follow strictly the README when you generate results.pkl and write the report,ask TA if you have any concern.
- If you apply model ensemble, the number of different models are 3.
- Except the external data we provided, other external dataset is not allowed.